mygrad.nnet.activations.selu#
- mygrad.nnet.activations.selu(x: ArrayLike, *, constant: bool | None = None) Tensor[source]#
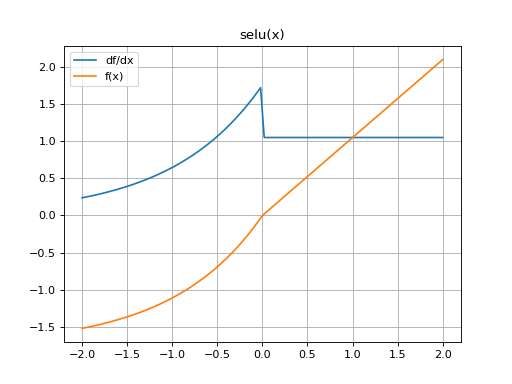
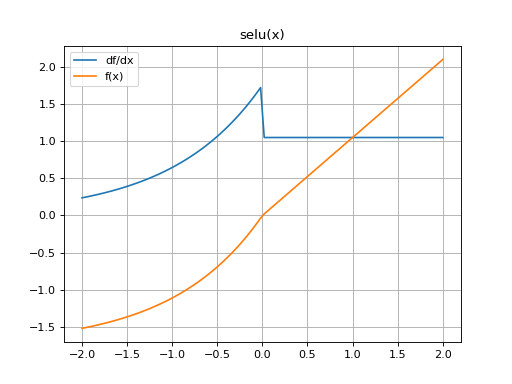
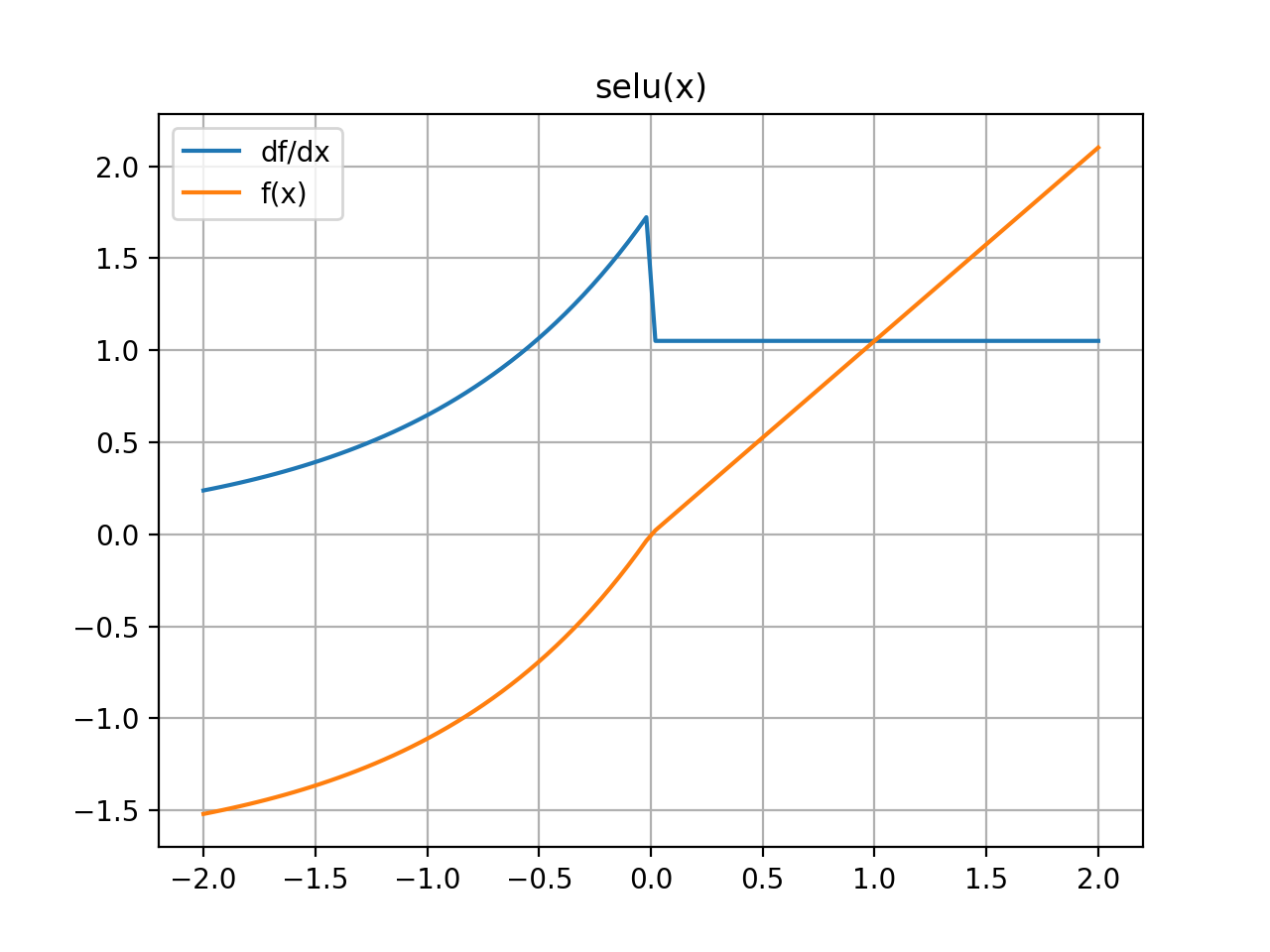
Returns the scaled exponential linear activation (SELU) elementwise along x.
The SELU is given by λɑ(exp(x) - 1) for x < 0 and λx for x ≥ 0.
- Parameters:
- xArrayLike
Input data.
- constantOptional[bool]
If
True, the returned tensor is a constant (it does not back-propagate a gradient)
- Returns:
- mygrad.Tensor
The SELU function applied to x elementwise.
References
[1]Günter Klambauer, Thomas Unterthiner, Andreas Mayr, Sepp Hochreiter Self-Normalizing Neural Networks https://arxiv.org/abs/1706.02515
Examples
>>> import mygrad as mg >>> from mygrad.nnet.activations import selu >>> x = mg.arange(-5, 6) >>> x Tensor([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5]) >>> y = selu(x, alpha=0.1); y Tensor([-1.74625336, -1.72589863, -1.67056873, -1.52016647, -1.11133074, 0. , 1.05070099, 2.10140197, 3.15210296, 4.20280395, 5.25350494])
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}