Vision Module
We will motivate this module using the same approach that we took in the audio module - by thinking about a neat trick that our phones can do. Many phones come with apps that can organize our photos for us, based not only on a picture’s metadata (e.g. the time and location where they were taken) but also on what or who are in the picture. For example, without our input the app can sort pictures of individuals into separate folders, making it easy for us to find all of the pictures of a parent or a friend. How can the app recognize who is in a picture? For that matter, how can the app understand the contents of a photograph at all?
What might seem like a mere convenience afforded to us by an app is actually the culmination of remarkable technical achievements in the field of computer vision. In short, this field asks: how can we enable computers to “understand” visual data in manners similar to that of humans? To be more precise, computer vision is a scientific field that devises theories, mathematical methods, and algorithms that enable us to distill high-level meaning from an image in systematic ways that do not directly rely on human cognition.
Computer vision is a broad field that draws widely from other fields such as signal processing, information theory, graph theory, and machine learning. With the relatively brief amount of time we will spend with this material, we will only have the opportunity to walk a narrow path through this field. In particular, we will focus on some recent developments in computer vision that have produced an explosion of interest and work; namely, we will view computer vision through the lens of machine learning, with a focus on supervised deep learning.
To kick things off, we will take a bird’s eye view of the field of machine learning (ML) to understand, broadly, how it contextualizes problems and intersects with the field of computer vision. Here, we will see that the general task of transforming observations into useful predictions or decisions is a major thrust of ML. Mediating this transformation is a mathematical model, which we must design to have the capacity to capture the critical relationships between the data that we will observe and the meaning that we hope to distill from them. Before we delve too deeply into what makes for a good mathematical model, we will reflect on what it means for a model (or a machine), to learn. While there are many different flavors of learning we will be focusing on supervised learning, whereby we can “teach” a machine by showing it the results that it should have predicted. In this context, we will study how so-called gradient-based learning, which is rooted in the gradient descent optimization scheme, provides us with an ability to automate the process of making fine-tuned adjustments to our model’s mathematical parameters, so as to improve the quality of its predictions.
Returning to the topic of mathematical models, a major challenge that machine learning practitioners face time and time again is the prospect of devising an appropriate mathematical model for each new problem that they tackle. The deep learning revolution has made major strides to help mitigate this challenge by putting forth ideas and techniques for designing “universal” mathematical models, which tend to take the form of neural networks. (To convey just how universal these models are becoming, a neural network based model that exhibited remarkable language comprehension ability was repurposed to solve challenging computer vision tasks). We will spend time understanding and working with basic neural networks, along with some of the crucial practical details that enable them to thrive.
This range of topics, brought together, will enable us to leverage convolutional neural networks along with unsupervised clustering techniques to create our own photo-sorting app! With a click of a button it will be able to organize photos of friends and families.
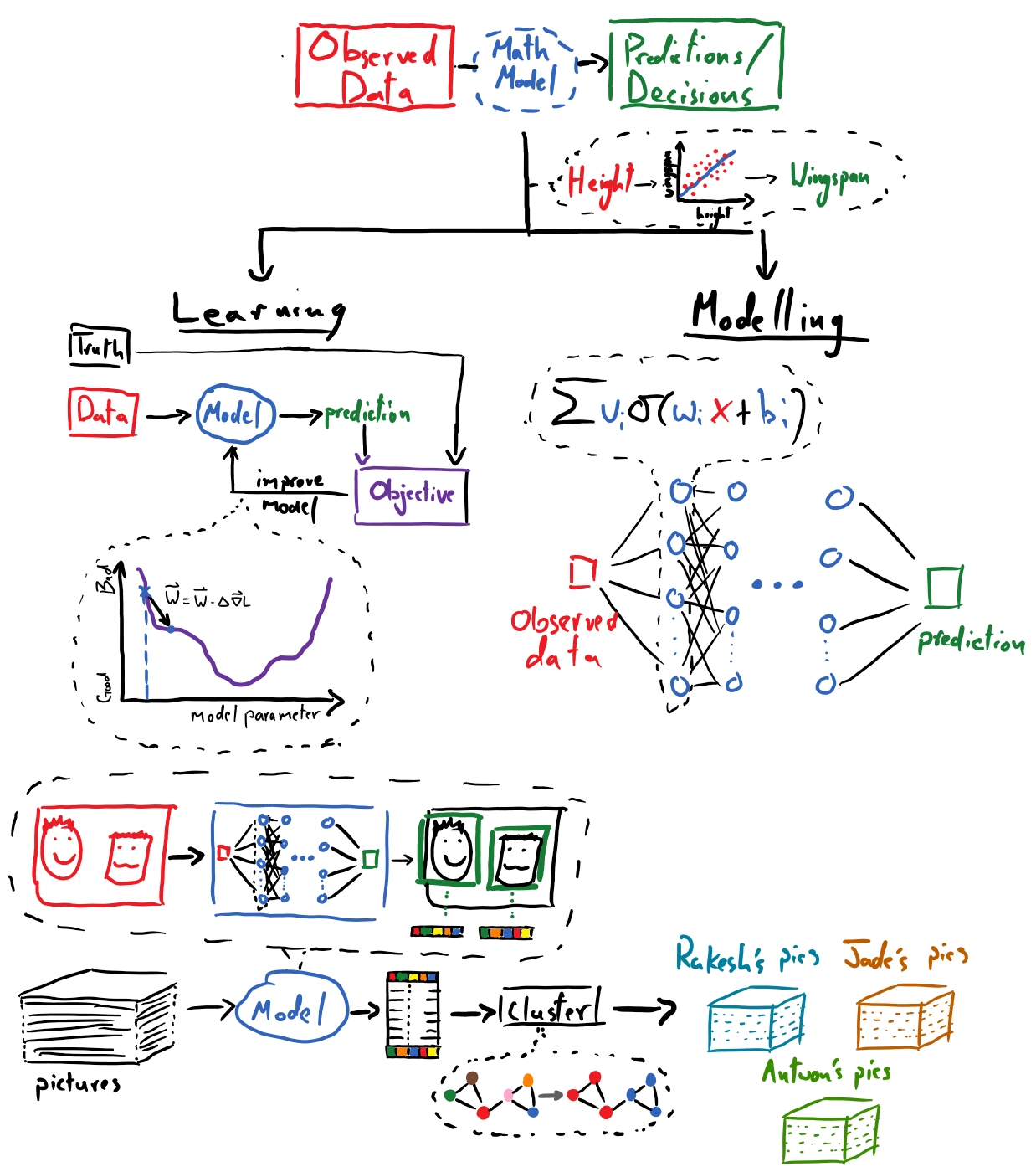
Contents:
- Prerequisites
- A Brief Introduction to Machine Learning
- Baby Steps Towards Machine Learning: Linear Regression
- Exercises: Exploring A Dataset
- Gradient-Based Learning
- Automatic Differentiation
- Exercises: Fitting a Linear Model with Gradient Descent
- Supervised Learning Using Gradient Descent
- Towards Neural Networks: The Modeling Problem
- Vision Module Capstone
- Whispers Algorithm