Whispers Algorithm
Note that there is a different version of these lecture notes available here: https://github.com/rsokl/WhispersLectureMaterials/blob/main/Whispers_Algorithm.pdf
It is recommended that you read the linked pdf document for a briefer, more accessible introduction, and then read this section.
In the second part of the capstone project, we want to be able to separate a group of pictures into groups of pictures of distinct individuals such that each individual in the database has a group of pictures. Note that each picture should only contain one person. For example, there would be two correct groups of a picture of two people who are both also in other pictures. We don’t want this to happen because an image can only be in one cluster. We will be working with these pictures in the form
of a 512-dimensional face descriptor vector which we will generate using facenet_pytorch’s trained resnet model.
Notice how this problem is different from the other part of the capstone:
There are no labels/truths accompanying each piece of data
We don’t know the possible “classifications” which are in this case the people that can be present in the images
Because of these, it becomes apparent that training a neural network will not work. We couldn’t produce a loss function without knowing the truths, and that is necessary for the model to backpropagate and learn.
Unsupervised Learning
This is where unsupervised learning comes in. We will be revisiting this topic more formally in week three, but here is a general introduction. This learning is unsupervised because the data does not come labeled - there is no point of reference to supervise by. However, this method allows for clustering of data. In this case, we will be grouping images using information from the cosine similarity between their descriptor vectors.
Note how much easier unsupervised training can be. It is less expensive in terms of both time and money because a large amount of data doesn’t need to be labeled. In addition, large datasets for learning are not needed anymore. It is important to really understand the structure of a problem and not develop an overkill solution. If all we need is to separate a set of images into the different people contained in the images, we don’t need to find or create and label a dataset. We also don’t need to worry about all the possible people the images could contain - or training a model.
Breaking Down the Algorithm
Before we dive into the implementation of the algorithm, we have to understand a structure utilized in whispers: the graph. The graph we are referring to isn’t related to the coordinate plane, but rather one with nodes and edges. Graphs are a large area of study, and we will only be touching on what is relevant for the whispers algorithm. A graph can come in various forms, but the most common graphical representation uses circles to represent nodes and lines to represent edges.
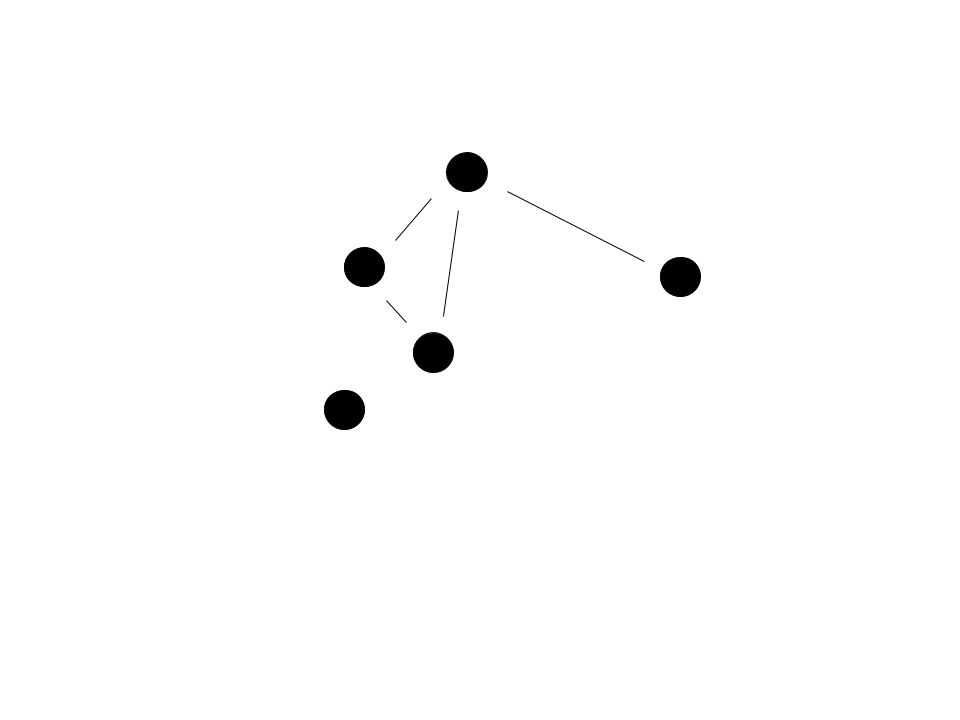
The nodes usually represent things and the edges the relationship between those things. In our case, the node represents an image and the edge a similarity to another image. Note how not all nodes have edges - think of this in our scenario as there being only one picture of a particular person in a set of images.
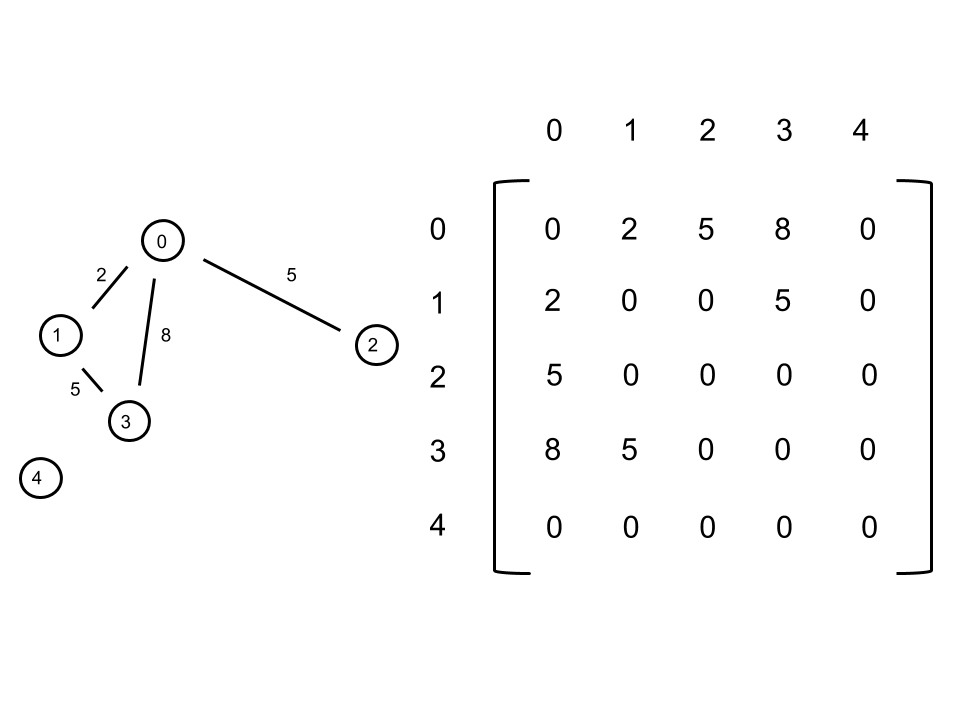
Now how do we represent a graph with code? A common method is known as the adjacency matrix. An adjacency matrix, \(A\) is an \(n\) by \(n\) matrix, with \(n\) being the number of nodes in the graph. \(A_{i, j}\) represents the relationship between nodes \(i\) and \(j\). In our case, \(A_{i, j}\) shows whether two nodes have an edge or not - \(1\) could signify having an edge and \(0\) not having one.
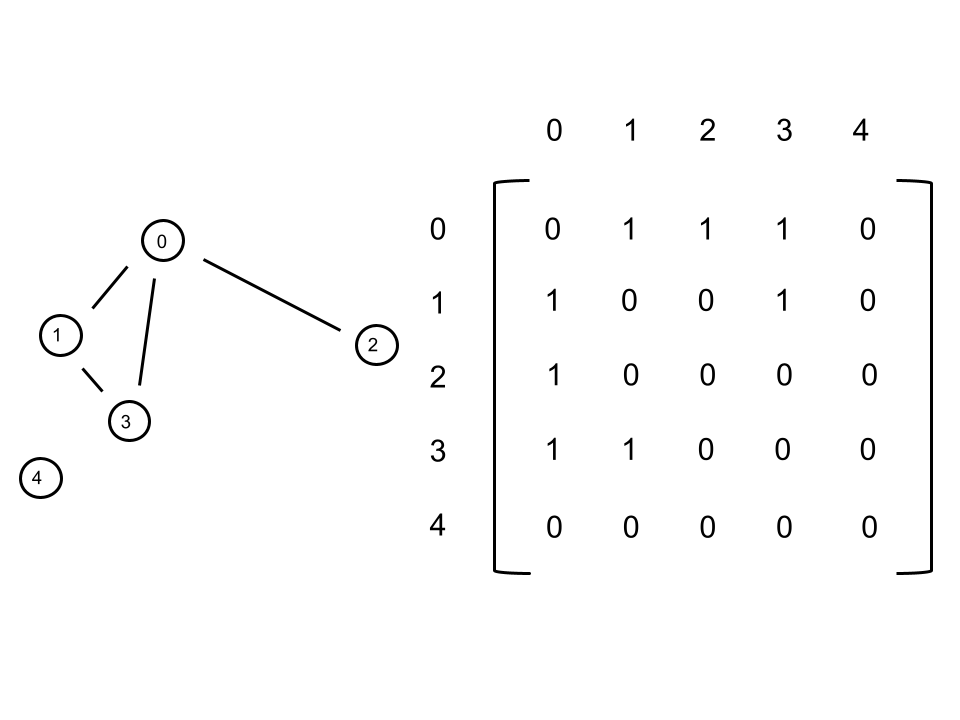
The indices in the matrix are representing nodes. Implementing a node class is recommended to keep things neat. Referring to the node.py class that is prewritten can be helpful. As a rule of thumb, we want the node object to include the following information:
label (which cluster it is a part of)
ID (a unique value in \([0,n-1]\), which can be the node’s index in the adjacency matrix)
neighbors (a list of the ID’s of the node’s neighbors)
The following steps outline the flow of the whispers algorithm:
Set up an adjacency matrix based on a cutoff
There is only an edge between two nodes, or images, if the two face descriptor vectors are “close enough” (note that when using cosine similarities, this translates to the distance between the vectors being less than the designated cutoff)
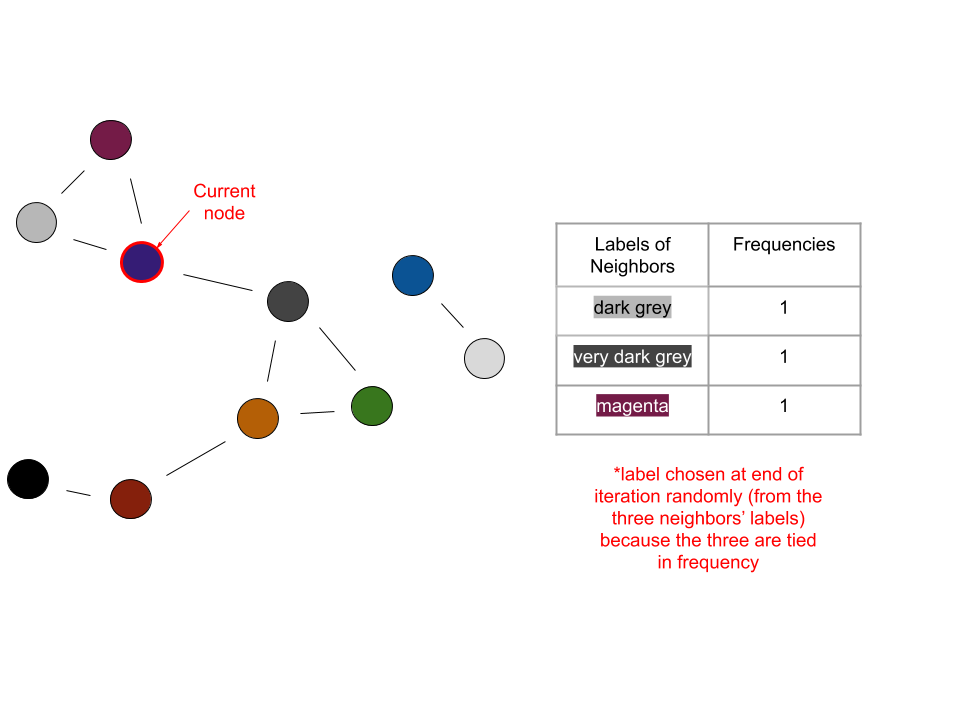
Initially each node has a unique label - the colors represent different labels

Pick a random node
Count the frequency of the labels (each corresponding to a cluster) of its neighbors
The current node takes on the label of the most frequent label determined in the previous step
In the case of a tie, randomly choose a label from those that are tied
Repeat this until the process converges (no change in number of labels) or a max number of iterations is reached
The previous four steps can be visualized as follows:
Iteration 1:
Iteration 2:
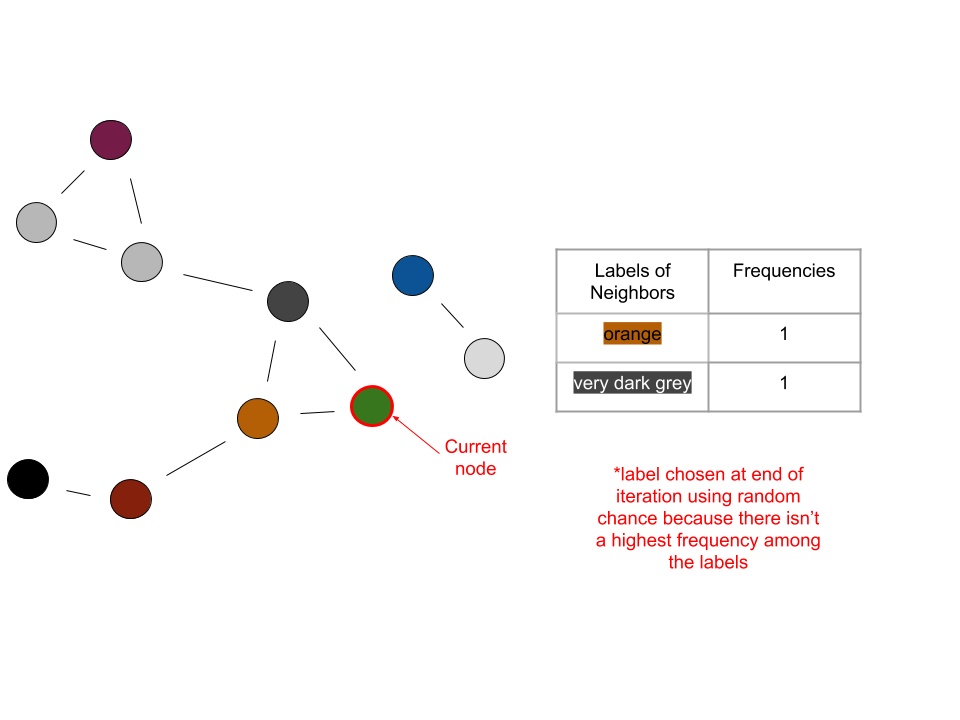
Iteration 3:
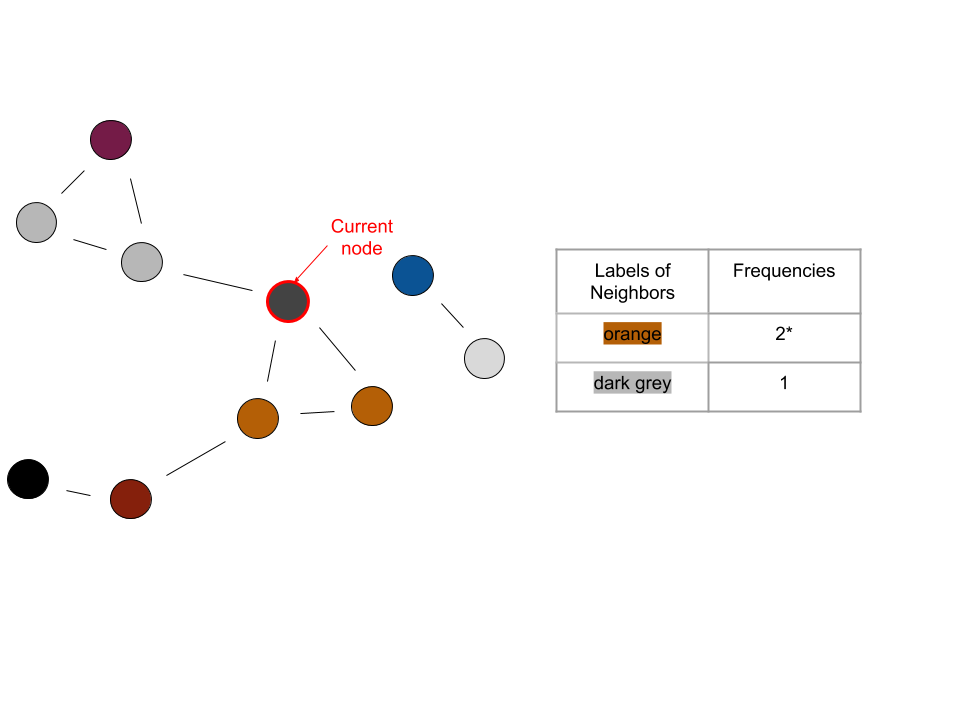
In the last iteration shown, the current node would become orange because orange is the most frequent label among its neighbors. When the number of labels converges, the end result could look like this:
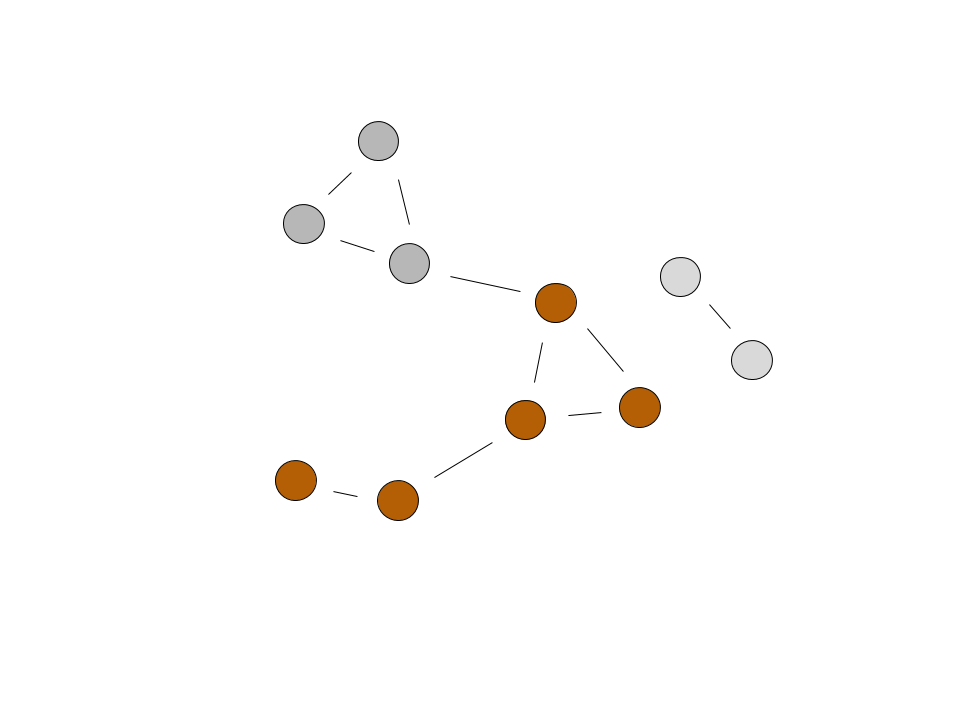
The final graph represents how the algorithm found three clusters of images, which corresponds to three different people.
Key Points
Some key ideas to keep in mind are:
We want edges between nodes we are confident are related (images whose face descriptors are similar within a set cutoff, which can be guided by a little experimentation)
We also want edges between nodes whose relationship is questionable - as we saw in the example graphs, some images had edges with others which were of a different person (we can accomplish this by having a looser cutoff)
We don’t want edges between all pairs of nodes
We want to have a max set number of iterations to run because there is a possibility that convergence will never occur
Because the first node and some labels are chosen randomly, there is a possibility of getting different results on different runs of the program on the same set of images
Because of the variability caused by this randomness, the whispers algorithm isn’t meant for really small sets of images - think about it like there is more scope for “correction” when there is an erroneous initial pairing of pictures in a large set
An image can only be in one cluster at any given iteration
For a better implementation of the whispers algorithm, use edge weights to aid choosing labels (refer to the next section)
Whispers Algorithm With Weighted Edges
We know that the closer together descriptor vectors are, the more similar the corresponding images are. However, in the implementation of the algorithm above, we are only using the vectors to determine whether nodes have edges or not. When a node has a tie among the frequency of the labels in its neighbors, we are randomly choosing a label from among those tied. However, what if we used the cosine similarity in determining which label to take on for each node? This would result in a more accurate choice of label, and in less sporadic behavior in smaller sets of images. A nuance in implementation would be to weight our edges using \(1/x^2\), with \(x\) being the cosine distance between the descriptor vectors. For convenience, we will be using cosine distance between two descriptors \(\vec{d_1}\) and \(\vec{d_2}\), which is given by \(1 - \frac{\vec{d_1} \cdot \vec{d_2}}{|\vec{d_1}||\vec{d_2}|}\).
This weighting makes it easier to find images that are truly close and of the same person - try it both with and without the weighting and see if a difference is noticeable. Now what does weighting an edge mean? It means that instead of there being a binary distinction in terms of connection between nodes (connected or not), there will be a scale among those that are connected. The ones that are closer in similarity will have a larger weight, which is determined using the \(1/x^2\) from above. Recall that cosine similarity returns a value from \(0\) to \(1\), with \(0\) meaning two vectors are identical and \(1\) meaning they are completely different (orthogonal). Using the \(1/x^2\) weighting results in a large weight for similar vectors. Implementing this is quite similar to what we had previously. Instead of simply putting a \(1\) in the adjacency matrix to signify an edge, we will have \(A_{i, j}\) contain \(1/x^2\).
Now determining which label to take on for each node can be broken down like this:
have a weight sum corresponding to each label among the node’s neighbors
for each neighbor, the weight of the edge between it and the node will be added to the sum corresponding to the neighbor’s label
the node will take on the label with the highest corresponding weight sum
The process can be visualized as follows:
Iteration 1:
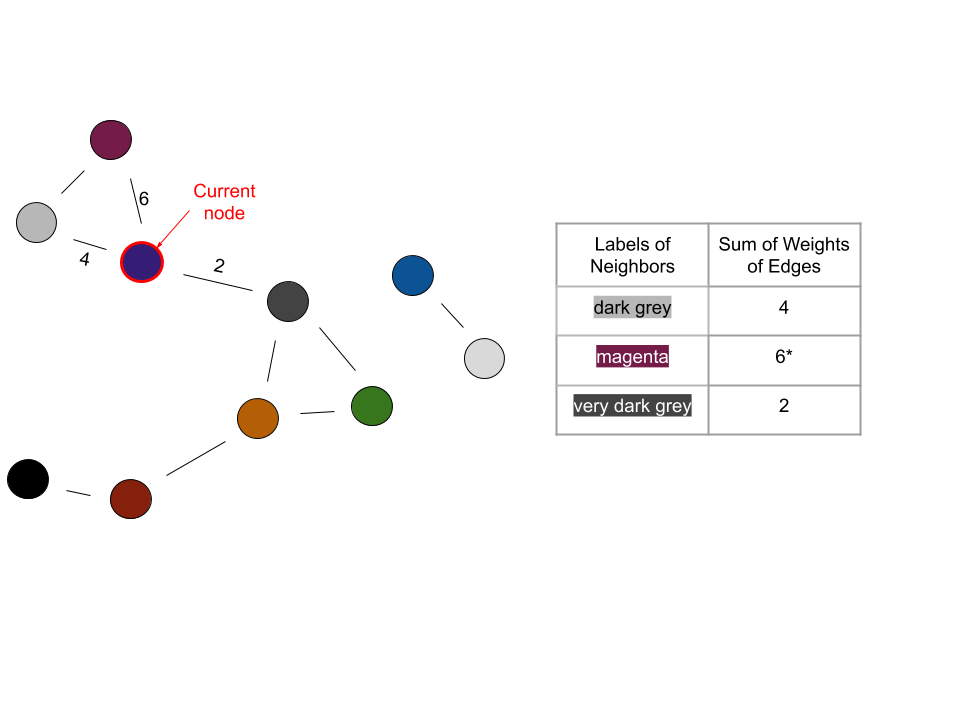
Iteration 2:
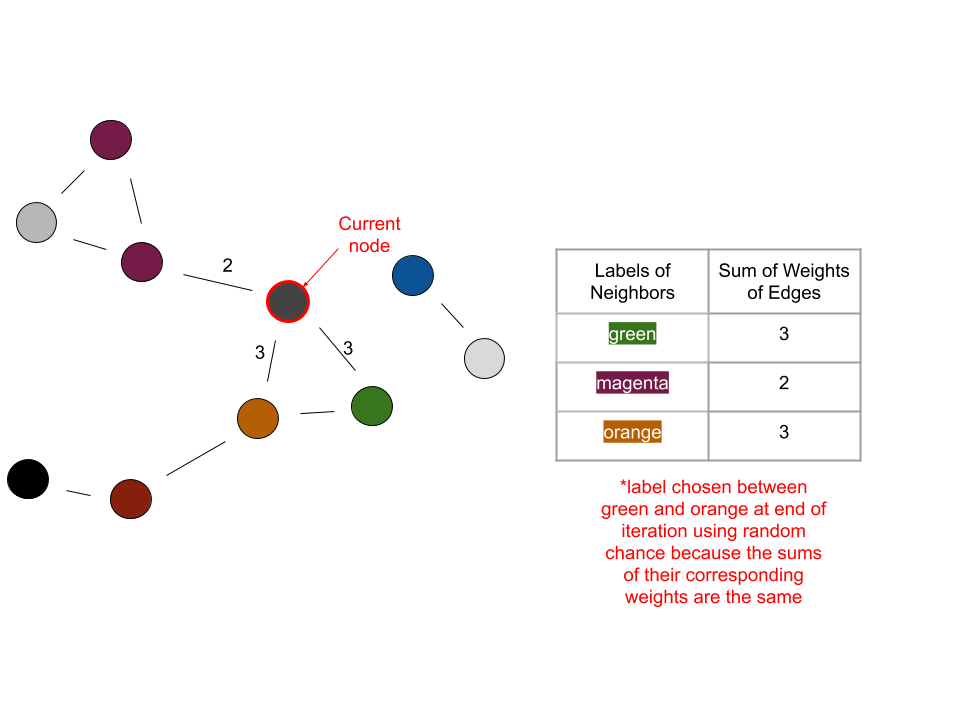
Iteration 3:
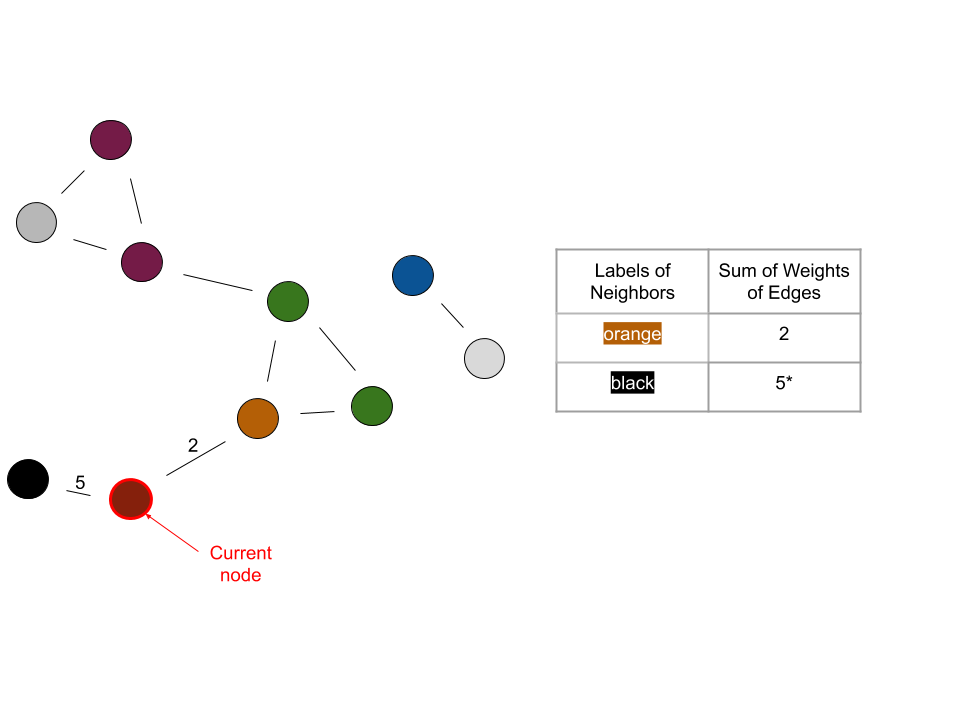
Notice how the weighted edges reduced the need to randomly choose a label. Using this method, choosing labels took place with an additional piece of information: a quantified similarity between a node and its neighboring nodes.
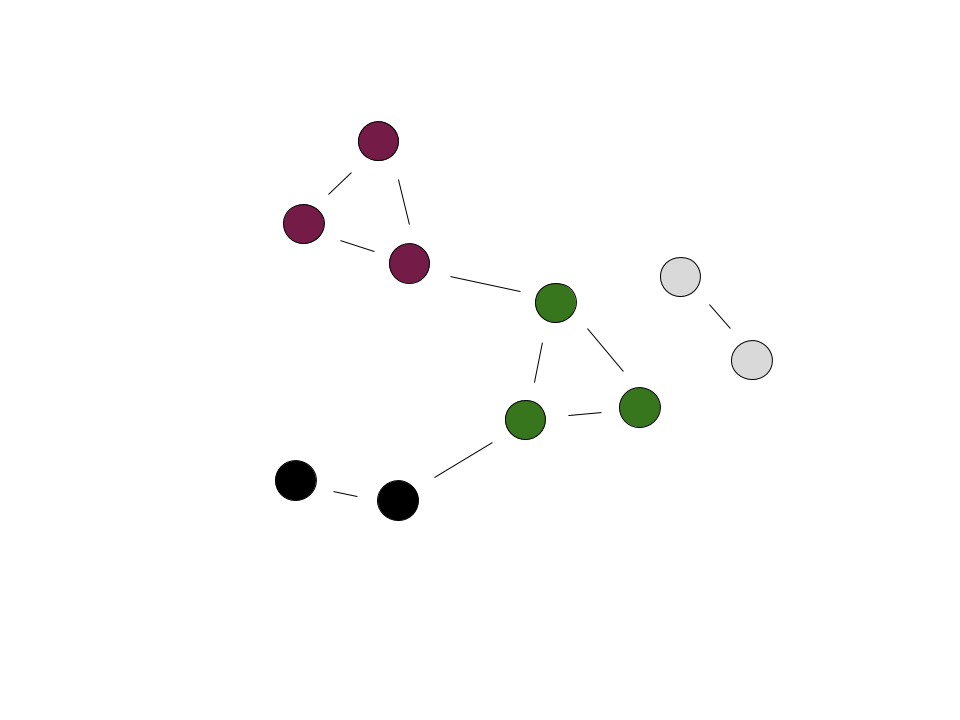
The resulting graph from the running the weighted whispers algorithm is different from the one obtained using the normal algorithm! Some of the clusters are composed of the same nodes, but have a different label. This doesn’t correlate to an actual difference in result - as long as the same images are grouped together, their corresponding label has no added significance. Moreover, this subtlety goes to show the role randomness can play in the whispers algorithm. However, a significant difference from before is the number of clusters: there are four instead of three. The cluster distinguished by the black label was previously grouped with another cluster. The implication could be that the normal whispers algorithm grouped two peoples’ pictures together. There are a few ways that chance could have played out that resulted in the merging of clusters. It could be a good exercise to think through one or two. Regardless, the increased robustness of the weighted whispers algorithm corresponds to leaving much fewer decisions to random chance. Overall, this results in the weighted algorithm having a higher accuracy.
Team Tasks
Here are some recommended tasks:
Define a
Nodeclass to store the information for a picture of a single individual from your pile of pictures (see below)Create a function that takes in a list of image-paths, and returns a list of nodes and an adjacency graph that describes the weighted connections between your nodes. This list of nodes and adjacency matrix, together, represent your graph.
You will need to estimate a maximum cosine-distance threshold for distinguishing nodes that share an edge (i.e. if \(\mathrm{cosdist}(\vec{d}_i, \vec{d}_j) < \mathrm{threshold}\) then node-i and node-j will share an edge). Note that this max cosine-distance threshold is also needed for the face-recognition database, so make sure that both legs of the project are collaborating to estimate this value and that you use the same value.
For your adjacency matrix, it is recommended that use weighted edges rather than 1s to represent edges. The recommended weighting function is \(\frac{1}{(\mathrm{cosdist}(\vec{d}_i, \vec{d}_j)) ^ 2}\)
Create a
connected_componentsfunction, which takes in your graph’s list of nodes, and returns a list of lists – each inner list contains all nodes with a common label.Create a
propagate_labelfunction that takes in a node, the node’s neighbors, and the adjacency matrix. It should update that node’s label based on the weights of its neighbor’s labelsCreate a
whispersfunction, which calls thepropagate_labelfunction some specified number of times on your graph. A node should be randomly selected each time thepropagate_labelsfunction is called.While the whispers function is running – and updated the graph’s labels – consider using your
connected_componentsfunction and record / plot how the number of connected components changes across iterations. At first each node should have its own unique label, and thus there should be as many connected components as nodes. But soon the number of connected components should decrease and converge to a stable number.
Gather a directory of pictures of, say, 10 distinct people. Each person should have 3-10 pictures. Create a graph from these pictures, run the whispers algorithm, and see if there is ultimately 10 connected components – one for each of the 10 distinct people.
Write code that will automatically organize the photos according to these connected component groupings
Useful Code
You will need to install networkx to use this code. First activate the appropriate conda environment, and then run:
conda install -c conda-forge networkx
The following code can be used to help us keep track of all of the pertinent information for each node in our graph. Also included is code that will plot our graph’s nodes and edges, and color each node based on its current label value. Thus nodes that have been clustered together by the whispers algorithm will have the same color.
import networkx as nx
import numpy as np
import matplotlib.cm as cm
import matplotlib.pyplot as plt
class Node:
""" Describes a node in a graph, and the edges connected
to that node."""
def __init__(self, ID, neighbors, descriptor, truth=None, file_path=None):
"""
Parameters
----------
ID : int
A unique identifier for this node. Should be a
value in [0, N-1], if there are N nodes in total.
neighbors : Sequence[int]
The node-IDs of the neighbors of this node.
descriptor : numpy.ndarray
The shape-(512,) descriptor vector for the face that this node corresponds to.
truth : Optional[str]
If you have truth data, for checking your clustering algorithm,
you can include the label to check your clusters at the end.
If this node corresponds to a picture of Ryan, this truth
value can just be "Ryan"
file_path : Optional[str]
The file path of the image corresponding to this node, so
that you can sort the photos after you run your clustering
algorithm
"""
self.id = ID # a unique identified for this node - this should never change
# The node's label is initialized with the node's ID value at first,
# this label is then updated during the whispers algorithm
self.label = ID
# (n1_ID, n2_ID, ...)
# The IDs of this nodes neighbors. Empty if no neighbors
self.neighbors = tuple(neighbors)
self.descriptor = descriptor
self.truth = truth
self.file_path = file_path
def plot_graph(graph, adj):
""" Use the package networkx to produce a diagrammatic plot of the graph, with
the nodes in the graph colored according to their current labels.
Note that only 20 unique colors are available for the current color map,
so common colors across nodes may be coincidental.
Parameters
----------
graph : Tuple[Node, ...]
The graph to plot. This is simple a tuple of the nodes in the graph.
Each element should be an instance of the `Node`-class.
adj : numpy.ndarray, shape=(N, N)
The adjacency-matrix for the graph. Nonzero entries indicate
the presence of edges.
Returns
-------
Tuple[matplotlib.fig.Fig, matplotlib.axis.Axes]
The figure and axes for the plot."""
g = nx.Graph()
for n, node in enumerate(graph):
g.add_node(n)
# construct a network-x graph from the adjacency matrix: a non-zero entry at adj[i, j]
# indicates that an egde is present between Node-i and Node-j. Because the edges are
# undirected, the adjacency matrix must be symmetric, thus we only look ate the triangular
# upper-half of the entries to avoid adding redundant nodes/edges
g.add_edges_from(zip(*np.where(np.triu(adj) > 0)))
# we want to visualize our graph of nodes and edges; to give the graph a spatial representation,
# we treat each node as a point in 2D space, and edges like compressed springs. We simulate
# all of these springs decompressing (relaxing) to naturally space out the nodes of the graph
# this will hopefully give us a sensible (x, y) for each node, so that our graph is given
# a reasonable visual depiction
pos = nx.spring_layout(g)
# make a mapping that maps: node-lab -> color, for each unique label in the graph
color = list(iter(cm.tab20b(np.linspace(0, 1, len(set(i.label for i in graph))))))
color_map = dict(zip(sorted(set(i.label for i in graph)), color))
colors = [color_map[i.label] for i in graph] # the color for each node in the graph, according to the node's label
# render the visualization of the graph, with the nodes colored based on their labels!
fig, ax = plt.subplots()
nx.draw_networkx_nodes(g, pos=pos, ax=ax, nodelist=range(len(graph)), node_color=colors)
nx.draw_networkx_edges(g, pos, ax=ax, edgelist=g.edges())
return fig, ax
Taking it Further
These are ideas to take your project further if your team has the time:
Display and label the results of the clustering (one possibility is in a grid view)
When the program is run on a folder of images, have it automatically create folders of the different people/clusters with the corresponding images in them