Vision Module Capstone
We will put our knowledge of neural networks and working with visual data to use by creating a program that detects and recognizes faces in a pictures, in order to sort the pictures based on individuals. The goal is to
take input from our camera
locate faces in the image and extract their “descriptor vectors”
determine if there is a match for each face in the database
return the image with rectangles around the faces along with the corresponding name (or “Unknown” if there is no match)
In the “Unknown” case, the program should prompt the user to input the unknown person’s name so they can be added to the database. Here is an example of what might be returned if the program recognizes everyone in the image

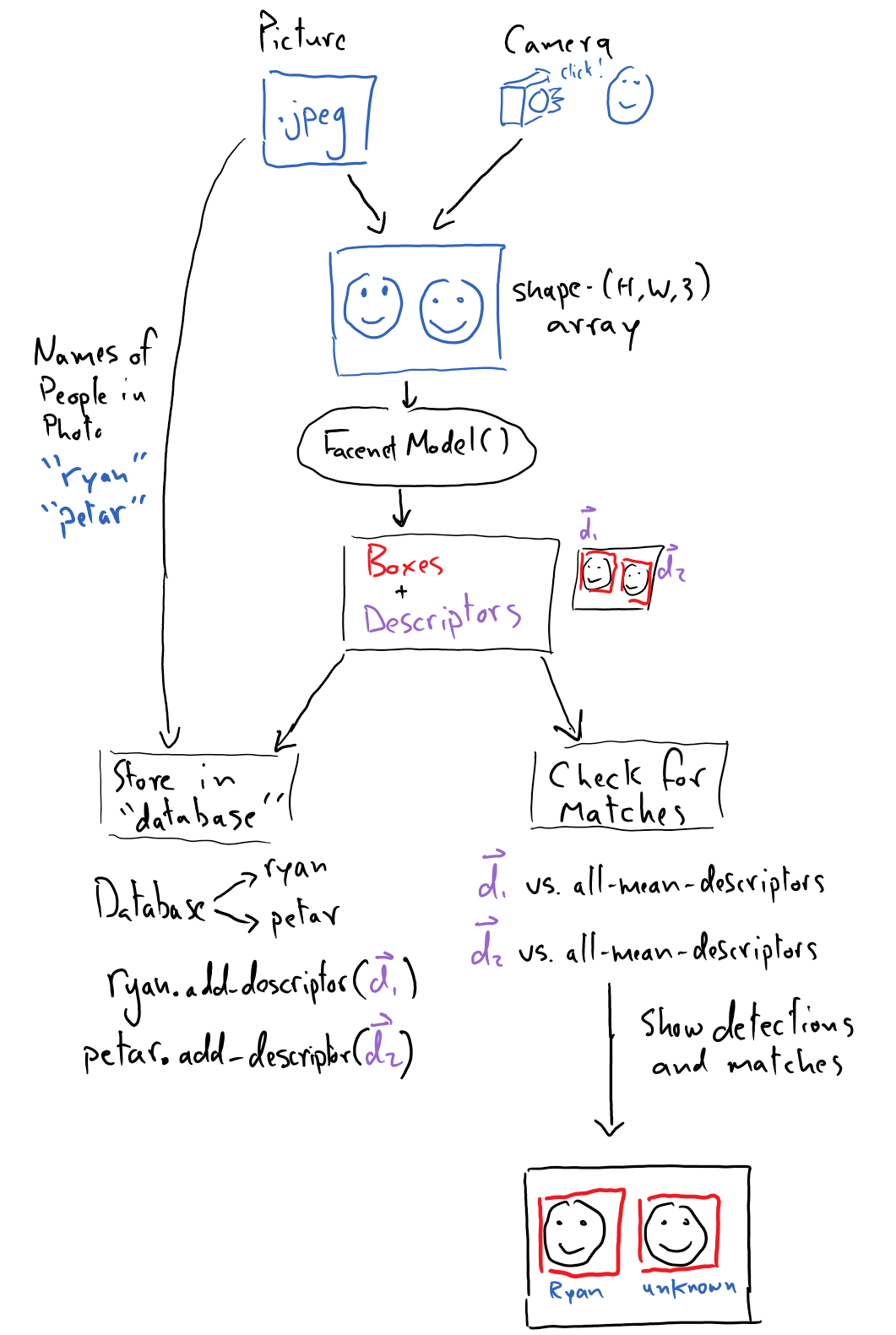
Let’s take a closer look at the pre-trained models we’ll be using to accomplish this.
Pre-Trained FaceNet Models
We will utilize two models from pre-trained neural networks provided by facenet_pytorch, via the facenet_models package. Both models are made accessible via a single class: FacenetModel
from facenet_models import FacenetModel
# this will download the pretrained weights for MTCNN and resnet
# (if they haven't already been fetched)
# which should take just a few seconds
model = FacenetModel()
Detecting Faces
The first is a model called a “multi-task cascaded neural network”, MTCNN, which provides face detection and alignments capabilities. Given an input image, the model will return a list of box coordinates with corresponding face-probabilities and face landmarks for each detected face.
# detect all faces in an image
# returns a tuple of (boxes, probabilities, landmarks)
# assumes ``pic`` is a numpy array of shape (R, C, 3) (RGB is the last dimension)
#
# If N faces are detected then arrays of N boxes, N probabilities, and N landmark-sets
# are returned.
boxes, probabilities, landmarks = model.detect(pic)
Using Detection Probabilities to Filter False Detections
At times spurious objects - like a basketball - can be detected as faces. However, these false detections usually have low “face-probabilities” associated with them. Thus we can filter out detections that fail to have high face-probabilities in order to avoid having false detections in our images. We need to figure out what a reasonable face-probability threshold is to do this. Perhaps we can try running the detector on a wider range of cluttered images in hopes to find some false detections, and then record what the face-probabilities are in associated with these objects versus those of true detections. From this we might estimate a sensible minimum probability threshold.
“Describing” Faces
# Crops the image once for each of the N bounding boxes
# and produces a shape-(512,) descriptor for that face.
#
# If N bounding boxes were supplied, then a shape-(N, 512)
# array is returned, corresponding to N descriptor vectors
descriptors = model.compute_descriptors(pic, boxes)
We will then use facenet_pytorch’s InceptionResnetV1, which is trained to produce 512-dimensional face descriptor vectors for a given image of a face. This model takes in the image and the detected boxes.
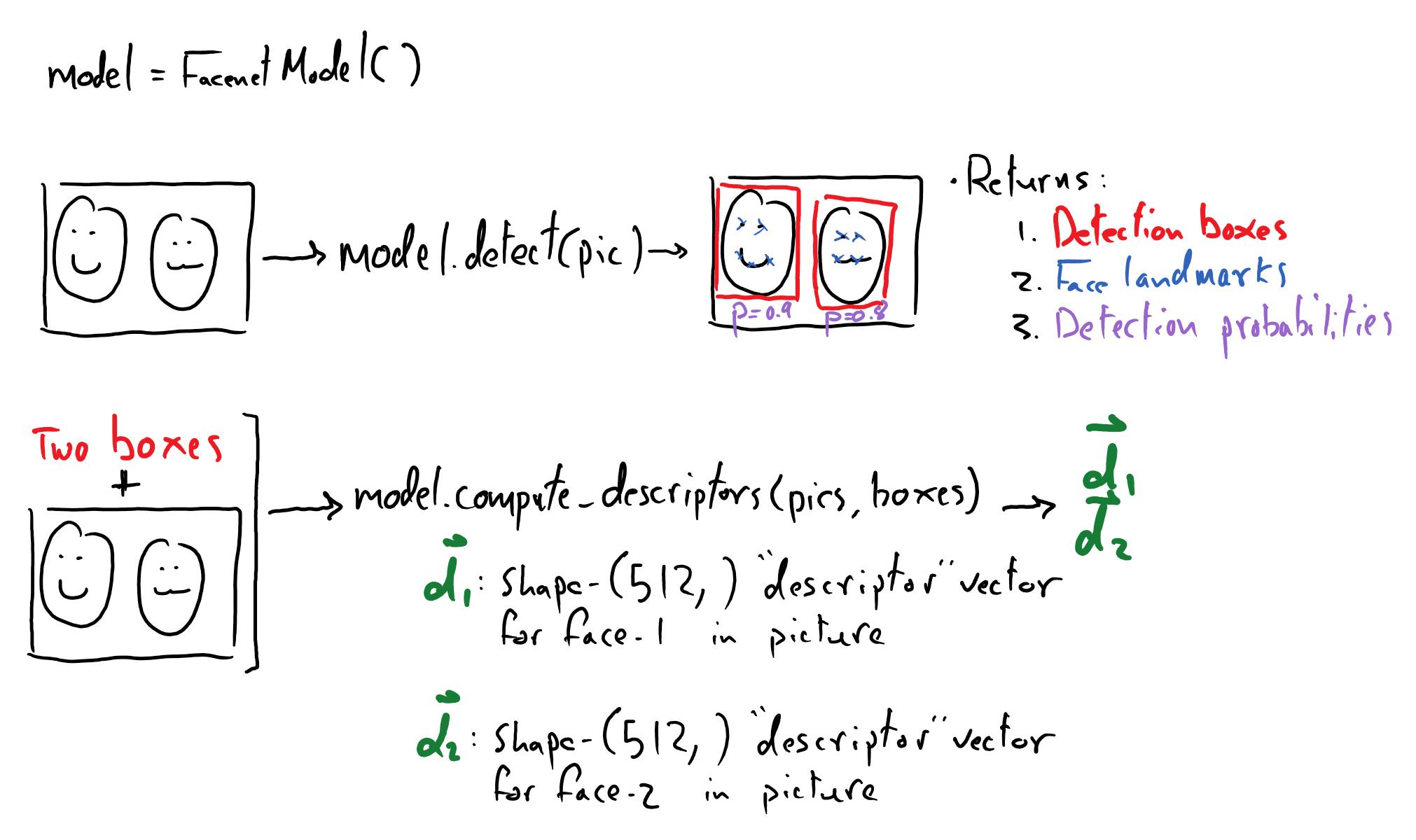
A facial descriptor vector is essentially an an abstract embedding of a face, which describes the face’s features in a way that is robust to changes in lighting, perspective, facial expression, and other factors, using only a 512-dimensional vector! These features are not necessarily concrete facial features like a nose and eyes, but more abstract representations that the model learned.
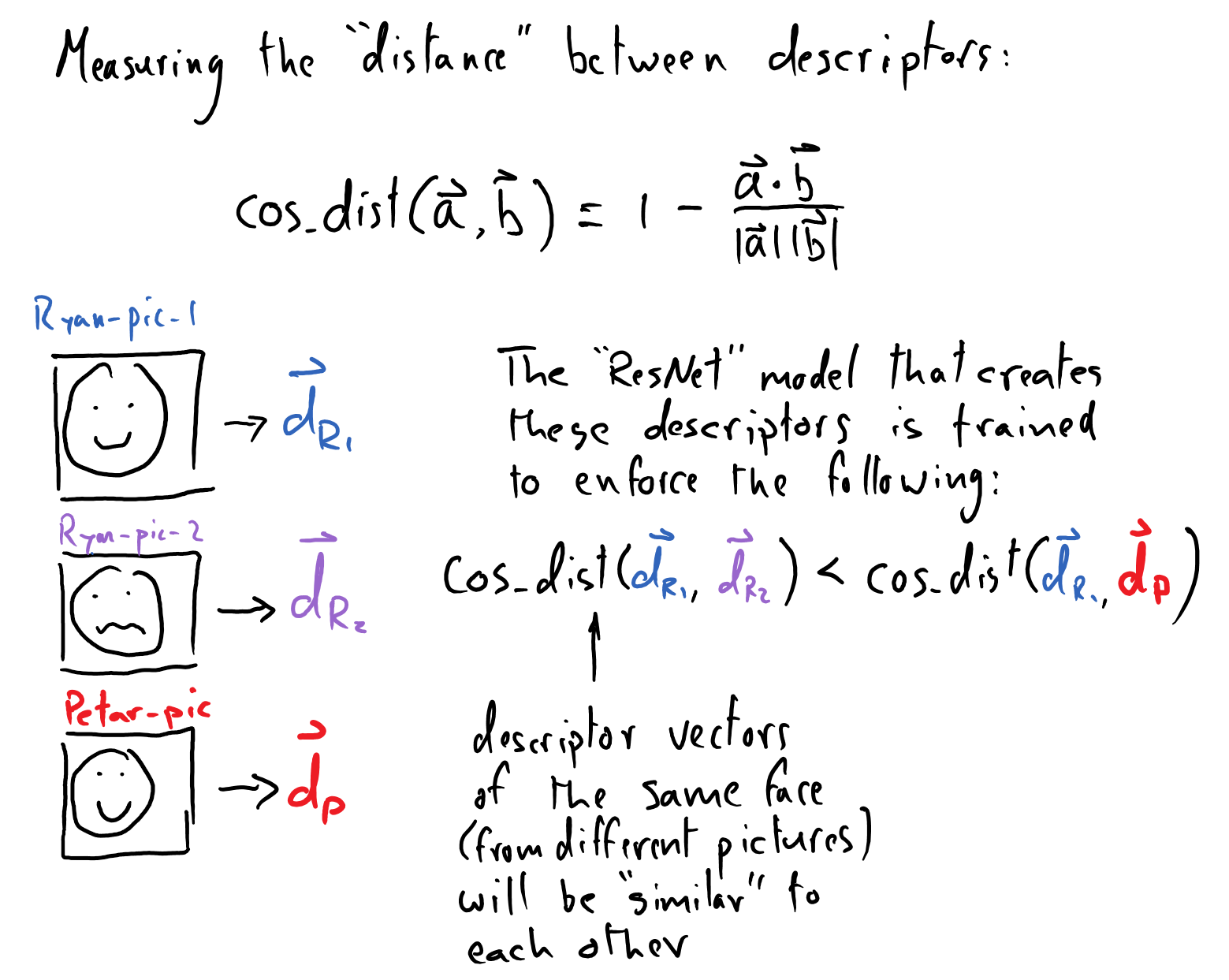
How did the model learn to produce such robust descriptor vectors? The model learned to create facial descriptors in this way by taking a triplet of pictures of faces, each consisting of two different pictures of the same person and a picture of a distinct person. The loss function then compares the pairwise dot-products between the descriptor vectors that are produced by the faces. The loss is designed to be minimized by ensuring that the descriptor vectors for the single individual are more
similar (have a larger dot-product) than those between descriptor vectors from different faces. By training over many triplets of different faces, the InceptionResnetV1is able to learn how to distill robust, distinguishing abstract features from a face in only a \(512D\) vector! You can read more about this in the FaceNet paper. This model was trained on the VGGFace2
dataset.
The principle that images of the same face have similar descriptor vectors allows us to “recognize” a face after it has been detected. If a detected face is “close enough” to a face in our database (the calculated distance between the face descriptors is below a certain cutoff), we can label the face with the appropriate name in the output image. Otherwise, we can prompt the user to enter the name corresponding to the unknown face.
Now that we have some familiarity with the tools we’ll be employing to accomplish facial recognition, let’s talk about how our database can be structured to keep track of our faces and add new ones when we find them.
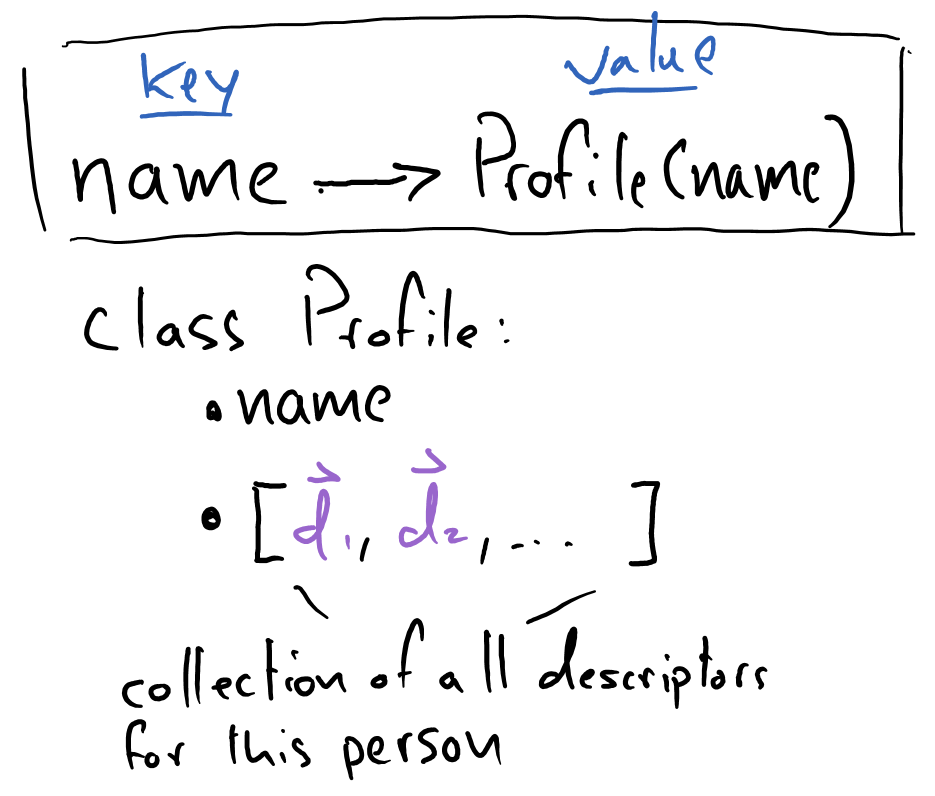
Database
Our face-recognition “database” will simply consist of a dictionary of \(\mathrm{name} \rightarrow \mathrm{profile}\) mappings, where, at a minimum, a “profile” contains a person’s name and a list of descriptor vectors (taken from a collection of different images of that person).
Make sure you’re familiar with Python’s dictionary data structure, which can be reviewed here on PLYMI. Another important tool to familiarize yourself with is the pickle module, which will allow you to store and load objects from your computer’s file system. PLYMI’s coverage of the pickle module can be found
here.
Recognizing Faces
How do we recognize a face in a new image using our neural networks?
We mentioned earlier that the nature of face descriptor vectors is that images of the same face should yield similar face descriptors. Thus, in order to identify if a new image is a match to any of the faces in the database we must mathematically compute the similarity between the new face descriptor and each of the averaged face descriptors in the database. I.e. for each person stored in our database, we will check the new descriptor vector against the average descriptor vector for that person.
This can be done with cosine distance, which is a measure of the similarity between two normalized vectors. Cosine distance can be computed by taking the dot product of two normalized vectors. Review “Fundamentals of Linear Algebra” for additional coverage on this topic.
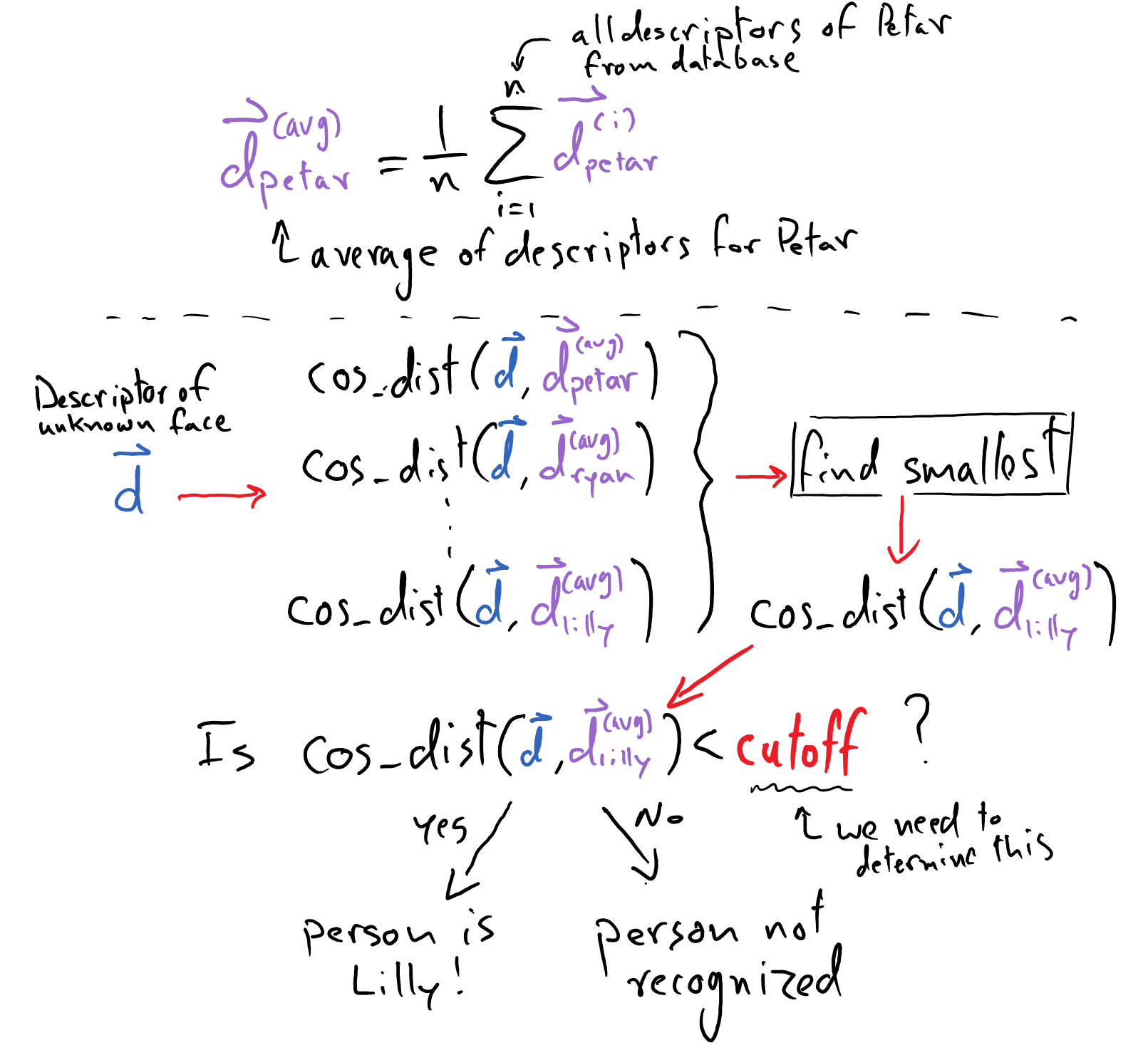
We can use cosine distance to compute the similarity between any two face descriptors, but how similar is “close enough” to validate a match? This is where a cutoff comes into play.
The cutoff indicates the maximum cosine-distance between two descriptors that is permitted to deem them a match. This value should be determined experimentally such that it is large enough to account for variability between descriptors of the same face but not so large as to falsely identify a face. If a face descriptor doesn’t fall below the cutoff distance with any face in the database, it is deemed “Unknown” and the user is prompted to enter a name. If the name exists in the database, the image should be added to that person’s profile. This situation may arise from a bad photo (bad lighting, something covering the face, etc.) or too strict of a cutoff (in this case, experiment with a slightly larger cutoff). If the name doesn’t already exist, you should make a new profile with that name and face descriptor.
Whispers Algorithm
The second part of this capstone project involves implementing an algorithm that can separate images into clusters of pictures of the same person. There will be one cluster for each person in our database. The implementation of this algorithm is explored in the following page.
Some Useful Code
Use the install and use the camera module so that you can take pictures using your webcam (or you can just use pictures from your phone).
The following code can be uses sci-kit image to read in an RGB image from various image file formats (e.g. .png or jpeg). To use this code, you must install scikit image. First, activate the conda environment that you want to install it in. And then run:
conda install -c conda-forge scikit-image
For some image formats there is a fourth channel - alpha - that can be used to measure opacity in a color. The models that we are using are only compatible with RGB images, so included is a check that will remove the alpha-channel from an image.
# reading an image file in as a numpy array
import skimage.io as io
# shape-(Height, Width, Color)
image = io.imread(str(path_to_image))
if image.shape[-1] == 4:
# Image is RGBA, where A is alpha -> transparency
# Must make image RGB.
image = image[..., :-1] # png -> RGB
Team Tasks
This has been a basic run-through of the concepts and tools you will use to create this capstone project. Here are some general tasks that it can be broken down into.
Create a
Profileclass with functionality to store face descriptors associated with a named individual.Functionality to create, load, and save a database of profiles
Functionality to add and remove profiles
Functionality to add an image to the database, given a name (create a new profile if the name isn’t in the database, otherwise add the image’s face descriptor vector to the proper profile)
Function to measure cosine distance between face descriptors. It is useful to be able to take in a shape-(M, D) array of M descriptor vectors and a shape-(N, D) array of N descriptor vectors, and compute a shape-(M, N) array of cosine distances – this holds all MxN combinations of pairwise cosine distances.
Estimate a good detection probability threshold for rejecting false detections (e.g. a basketball detected as a face). Try running the face detector on various pictures and see if you notice false-positives (things detected as faces that aren’t faces), and see what the detectors reported “detection probability” is for that false positive vs for true positives.
Estimate the maximum cosine-distance threshold between two descriptors, which separates a match from a non-match. Note that this threshold is also needed for the whispers-clustering part of the project, so be sure that this task is not duplicated and that you use the same threshold. You can read more about how you might estimate this threshold on page 3 of this document
Functionality to see if a new descriptor has a match in your database, given the aforementioned cutoff threshold.
Functionality to display an image with a box around detected faces with labels to indicate matches or an “Unknown” label otherwise
Also visit the following page for a discussion of the whispers algorithm, which we will use to sort unlabeled photos into piles for unique individuals.
Links
“Fundamentals of Linear Algebra” - CogWeb - link needs to be changed when official website is published