Natural Language Processing
Introduction to AI
So far, you’ve learned how to get your computers to understand sound and images. This week we’ll be extending that to language. Then you’ll have almost all the pieces for building an AI agent that can hear, see, and communicate with language.
Defining AI
There are many ways of defining artificial intelligence.
According to Chollet in Deep Learning with Python, AI “automate[s] intellectual tasks normally performed by humans.” In Artificial Intelligence: A Modern Approach by Russell and Norvig, it is described as having two dimensions: either abstract versus physical, or human versus rational. The latter is expanded on, with relation to acting and thinking:
Thinking humanly is the “cognitive modeling” approach. It determines how humans think through introspection, psychological experiments, and brain imaging. The idea is that once a theory of the mind is formulated, it can be expressed as a computer program.
Thinking rationally is the laws of thought approach. It contains precise notation for statements about objects and relations among them. There are rules for yielding correct conclusions from premises i.e., logic.
Acting humanly is the “Turing Test” approach. A computer passes the Turing Test if a human interrogator can not tell whether written responses come from a person or a computer. The total Turing Test includes video feed and hatch for passing physical objects.
Acting Rationally is the “rational agent” approach. It creates agents that operate autonomously, perceive the environment, persist, adapt, and create and pursue goals. Rational agents act to achieve the best outcome (or best expected outcome in face of uncertainty).
These four bring up questions. For example, in the history of flight: did we need to model flying machines on nature? Or did we need to just solve the problem of flight in whatever way worked? For self-driving cars: do we want them to drive optimally, or mimic human drivers? This is just something to keep in mind as we’re building intelligent machines.
Milestones of AI
1997 IBM Deep Blue defeats reigning chess champion (Garry Kasparov)
2002 iRobot’s Roomba autonomously vacuums the floor while navigating and avoiding obstacles
2004 NASA’s robotic exploration rovers Spirit and Opportunity autonomously navigate the surface of Mars
2007 DARPA Grand Challenge (“Urban Challenge”): for autonomous cars to obey traffic rules and operate in an urban environment
2009 Robot Scientist “Adam” discovers new scientific knowledge, and it is able to perform independent experiments to test hypotheses and interpret findings
2011 IBM Watson defeats former Jeopardy! champions (Brad Rutter and Ken Jennings)
2014 “Eugene” (program that simulates a 13 year old boy) passes Turing Test at University of Reading event (mistaken for human by more than 30% of judges)
2015 DeepMind achieves human expert level of play on Atari games (using only raw pixels and scores)
2016 DeepMind AlphaGo defeats top human Go player (Lee Sedol)
2018 IBM Project Debater
The following are virtual assistants that use natural language to answer questions, make recommendations and perform actions.
2011 Apple’s Siri virtual assistant released (iPhone 4S)
2014 Amazon Alexa virtual assistant released (Echo. It can control smart devices and be extended with skills)
The Landscape of AI
As we have seen, there are lots of AI techniques used to achieve amazing feats! The diagram below (Chollet Fig 1.1) captures how AI, machine learning, and deep learning are related.
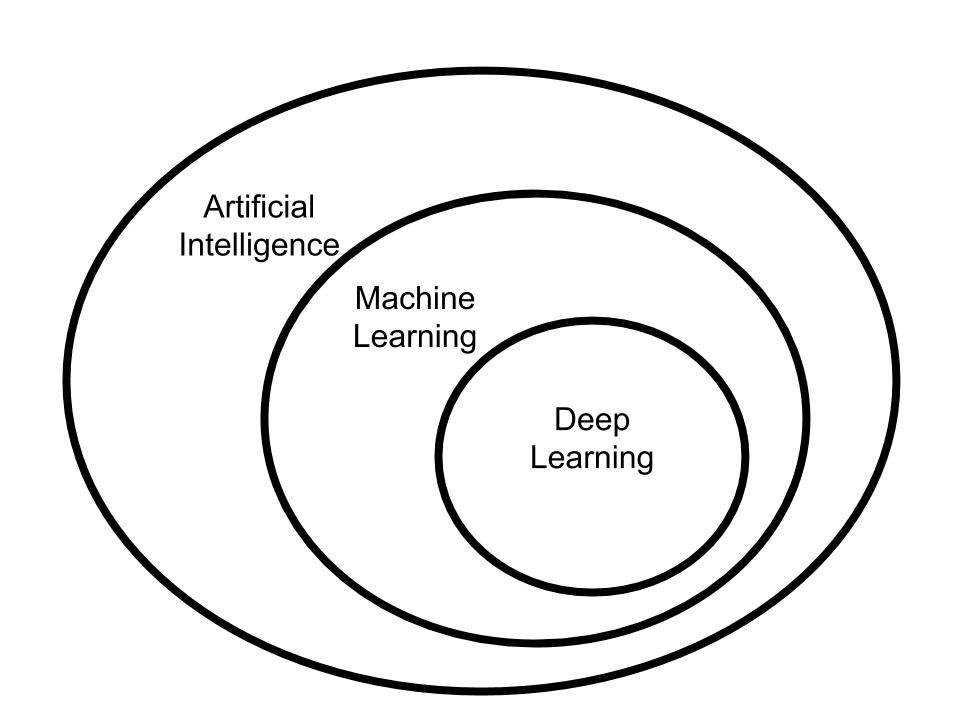
The current concepts on AI are from the 1950s. The Turing Test is from 1950 and in 1956, the term artificial intelligence was coined in the Dartmouth College summer AI conference. AI encompasses “symbolic AI”, which is a set of explicit hard-coded rules for manipulating knowledge. This is found in expert systems for medical diagnosis and traditional chess programs. Examples of artificial intelligence include the minimax search and theorem proving.
Machine learning is the ability to learn from experience, and its workings are delineated in the figure below.
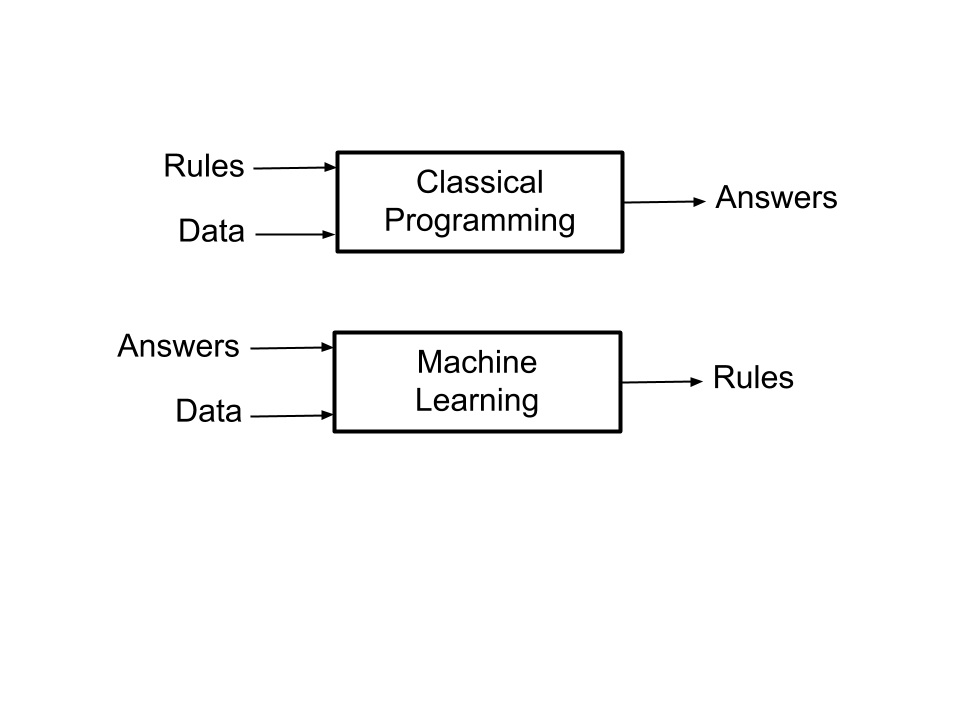
Machine learning focuses on training rather than programming. The techniques used include decision trees, logistic regression, and support vector machines. Examples of ML include decision trees and support vectors machines.
Deep learning, which is a form of machine learning, is where we are. It originates from the early 2010s and is hierarchical representation learning. This means that learning occurs in successive layers of increasingly meaningful representations that get closer to expected output. There has been a lot of progress and several breakthroughs in image classification, speech recognition, machine translation, autonomous driving, and game playing.
Are We Done?
Well, we are still far from human-level artificial general intelligence. Tests associated with this are the coffee test formulated by Wozniak and the flat pack furniture test by Tony Severyns. In the coffee test, a machine is required to enter an average American home and figure out how to make coffee: find the coffee machine, find the coffee, add water, find a mug, and brew the coffee by pushing the proper buttons. In the flat pack furniture test, a machine is required to unpack and assemble an item of flat-packed furniture. It has to read the instructions and assemble the item as described, correctly installing all fixtures.
Introduction to NLP
What is NLP
Natural language processing, or NLP, is a subfield of AI that deals with techniques and systems for handling spoken or written language. Natural language understanding, NLU, and natural language generation, NLG, are branches of NLP. It is important to consider what language means. According to Wikipedia, “Language is the ability to acquire and use complex systems of communication, particularly the human ability to do so.” We will not be diving too deep into linguistics. We will focus on how to get computers to do things that we would normally consider requiring the ability to understand and use language and even the ability to think.
Some of the tasks NLP can be used for are:
answering questions
natural language query interfaces
image captioning (spanning both computer vision and language)
authorship ID (identifying the author(s) of different works)
plagiarism detection
automatic essay grading
dialog systems (a computer conversing with a human)
voice user interfaces (speech-to-text and voice commands for technology)
document summarization
document retrieval (based on keyword searches, etc)
document classification (based on main topic(s) covered)
document clustering (grouping similar documents)
document recommendation (based on history of documents read, etc)
Levels for Analyzing Language
At the most basic level, language is a signal or sequence that is either analog (speech) or digital (text). We will be focusing mostly on text, of which there is an abundance due to the internet.
Here is a sample sentence: “A dog is chasing a boy on the playground.” We can view and analyze it on several levels of increasing complexity: sequence of letters from an alphabet, sequence of words (note that not all languages have easily recognizable word boundaries, e.g., Chinese), part-of-speech tags, syntactic structure, entities and relationships, and logic predicates.
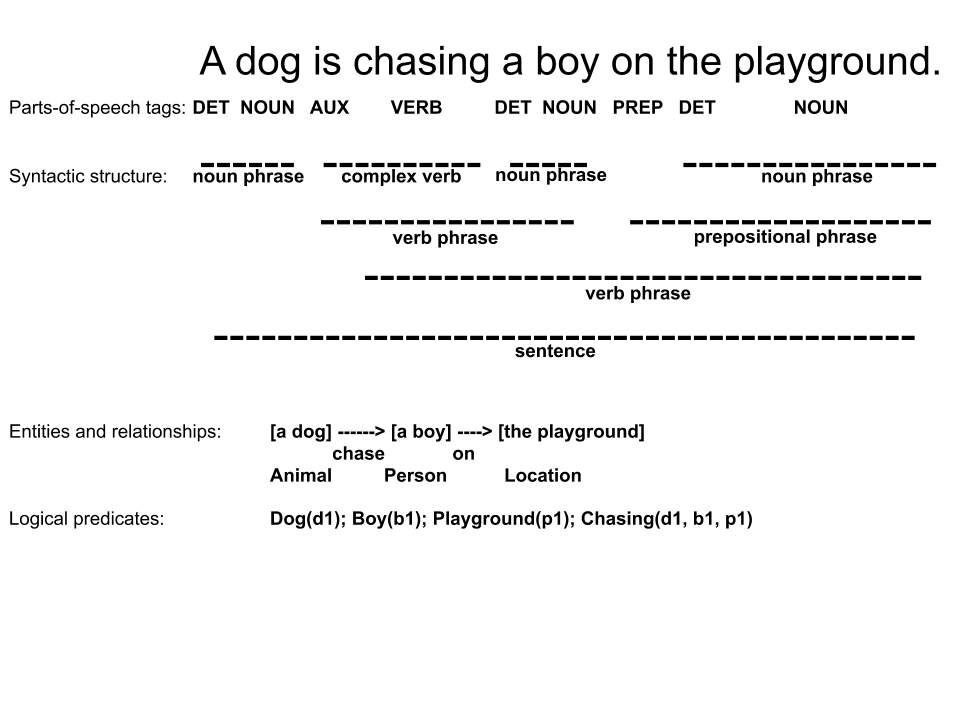
The farther down we go, the closer we get to extracting and representing the knowledge inherent in the sentence. We will be starting at a higher level because there is a lot that can be done while not explicitly dealing with parsing the tree of a sentence. Similar to using raw pixels for computer vision, deep learning methods often can use raw words or characters as inputs. This is possible because neural networks can learn hierarchical features automatically.
However, there are intricacies that make processing language hard. Ambiguity is one issue. For example the sentence “We saw her duck.” could be referring to an aquatic bird, someone avoiding being hit, or a cutting tool. Sarcasm is another issue. For example, double negatives like “I don’t not like it” convey a different meaning from their non double negative counterparts like “I do like it.”
Intro to Language Modeling
When modeling language, we can think about the probability of a sequence of words or characters:
For example, in English, “the black cat” is much more likely to occur than “the cat black.” This model could be used in language id: how likely is a piece of text to be from a particular language? It could be used in machine translation: after generating a bunch of possible translations for a sentence, they could be ranked according to how natural (or probable) they are according to a language model of the target language.
An important type of language model is called the n-gram language model. This truncated “history” to (n-1) words.
So for a trigram model: \(P(w_i|w_{i-2}, w_{i-1})\), which in our case would be: \(P(cat|the, black)\)
These probabilities can be estimated by counting relative frequencies in a training corpus.
A different approach is the “bag of words” approach. In this model, the frequencies within a set of words are measured across different pieces of text. It is important to note that order and grammar are lost. In addition, the set of words the model tracks must be chosen wisely. For example, removing generally meaningless words that provide grammatical structure, like “the” and “on”, is good practice. These words are referred to as stop words. This model can be used in machine learning for document classification. Inferences can be drawn on the contents of a document based on combinations of different frequencies. For example, a document with the most frequent word being “slide”, the second most frequent word being “swing”, and the third being “kids” might be describing a playground.

Some of the conclusions that could be drawn from the bag of words representations above is that documents one and two are more similar due to a bigger overlap in their key terms. They could be classified as describing common pets while document three could be classified as describing taekwondo.
When thinking about choosing a good vocabulary, Zipf’s Law helps to quantitatively show which set of words to concentrate on. For the data that Zipf’s Law applies to, if the elements in a large data set are ranked with the element in rank one being the most common, there is an inverse proportional relationship between the frequency and rank of each element. Zipf’s Law applies to both word and character frequencies. In other words, the most frequent word in a large corpus occurs twice as much as the second most common word, three times as much as the third most common word, and so on. This means that half of the corpus is comprised of one word.
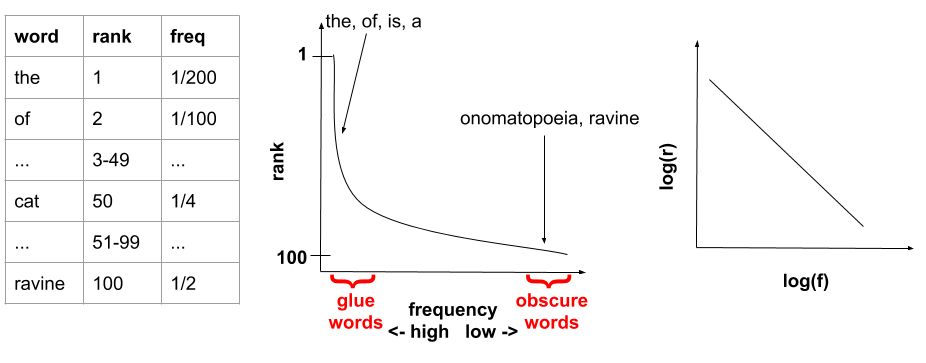
Therefore, it is best to ignore the most and least common words. The most common words tend to be “glue” words like and, a, and the and provide no insight into how to distinguish between sets of texts. The least common words might be too specialized and end up acting like a fold in a flashcard for a NN. The NN could end up correlating the fold with the answer. This could mean latching onto a word that occurs once or twice in the training corpus to correctly classify a specific text which means it is not learning correctly.